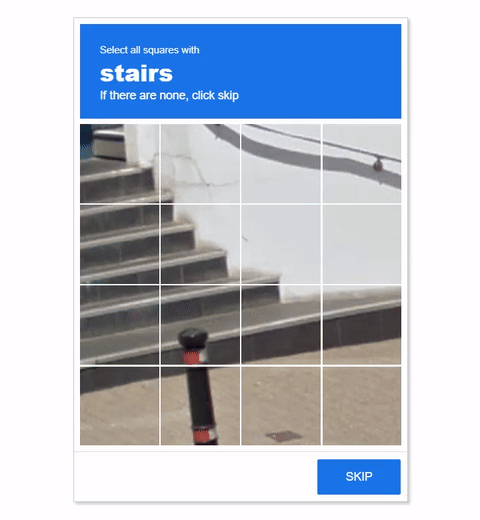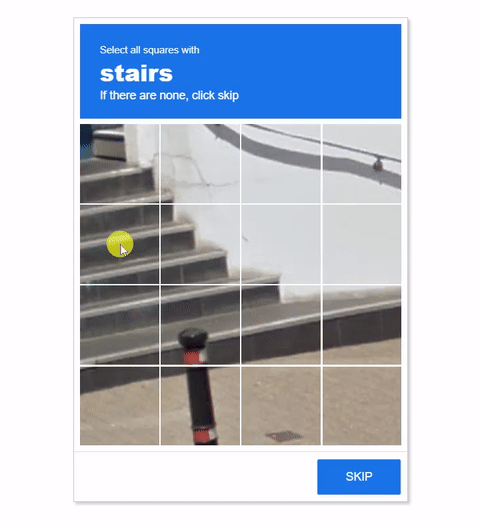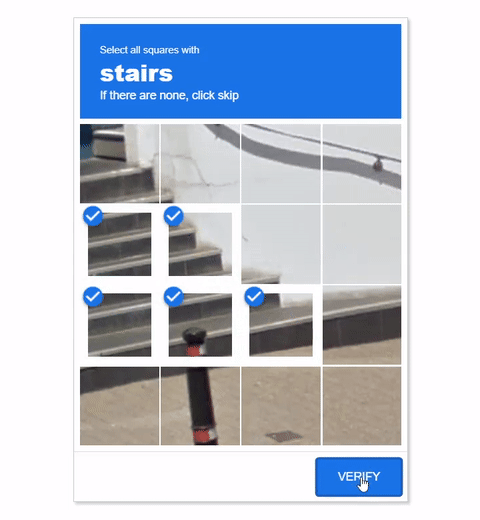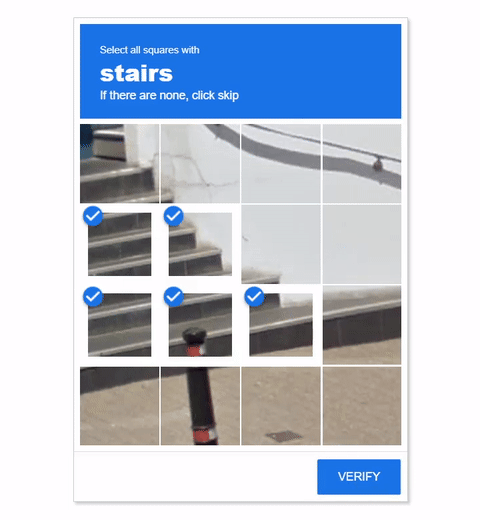
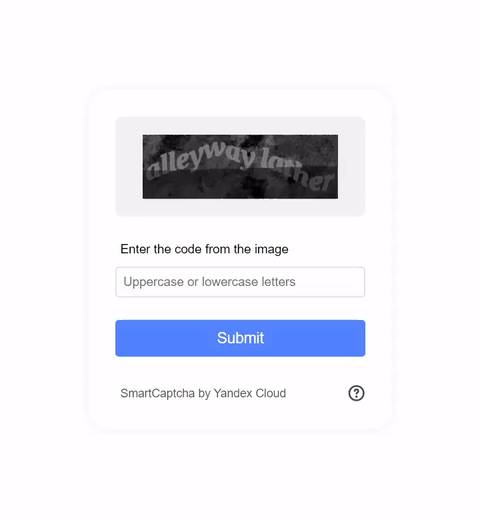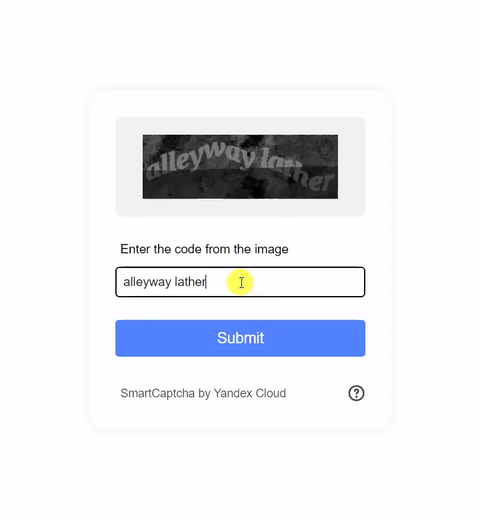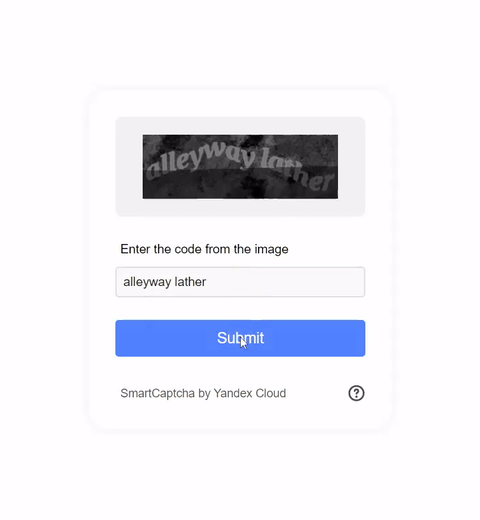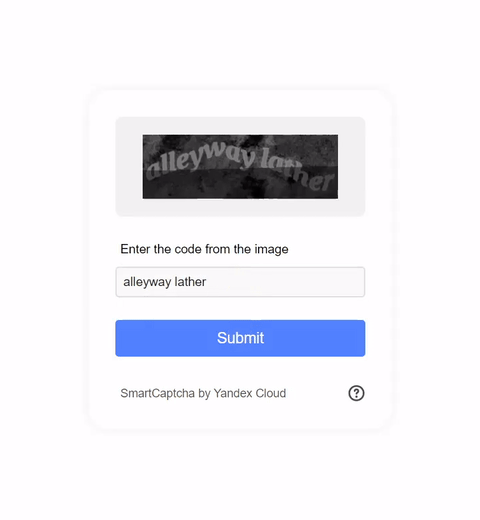
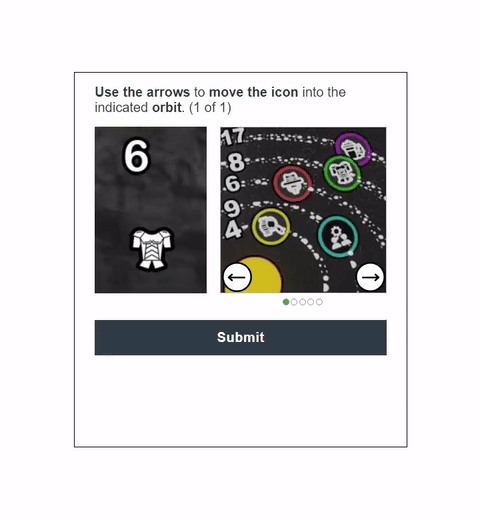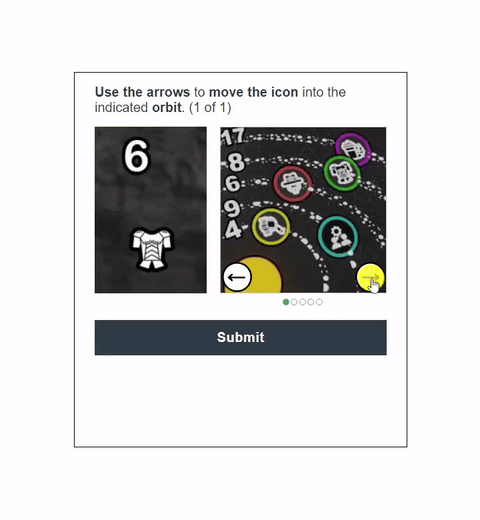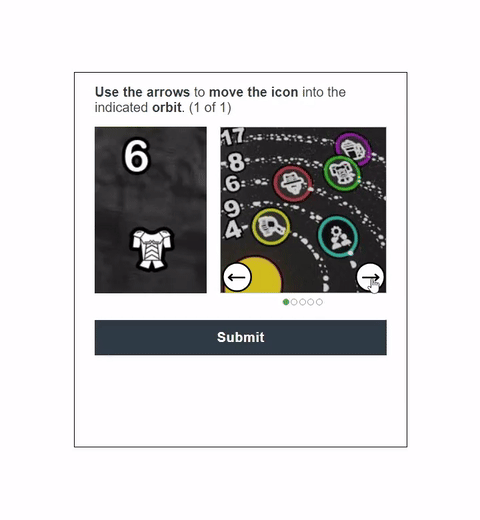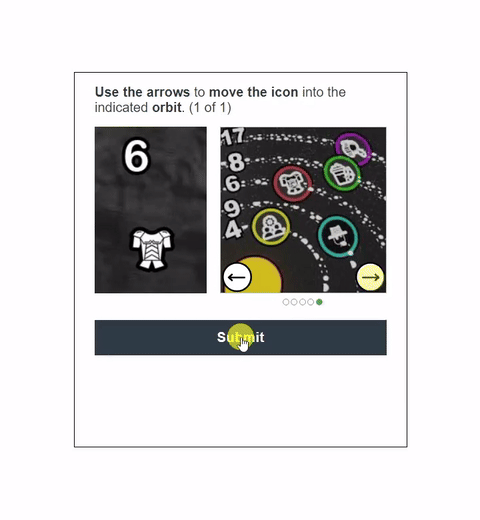
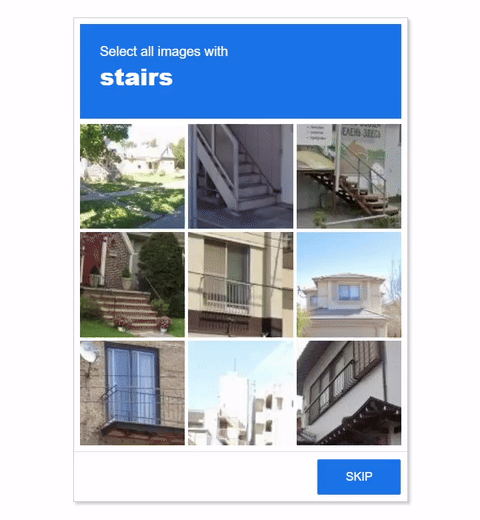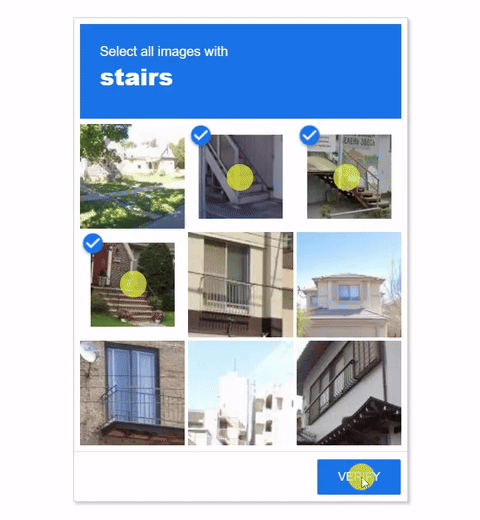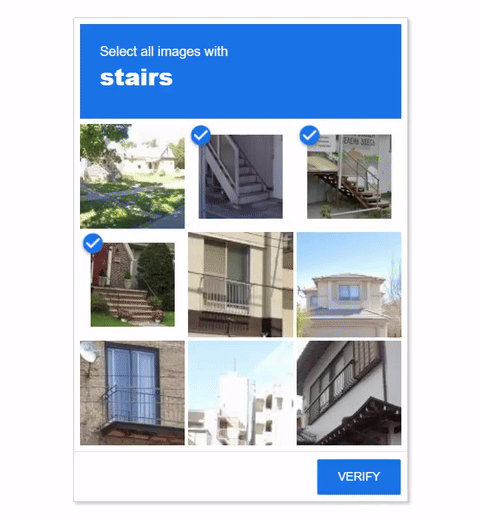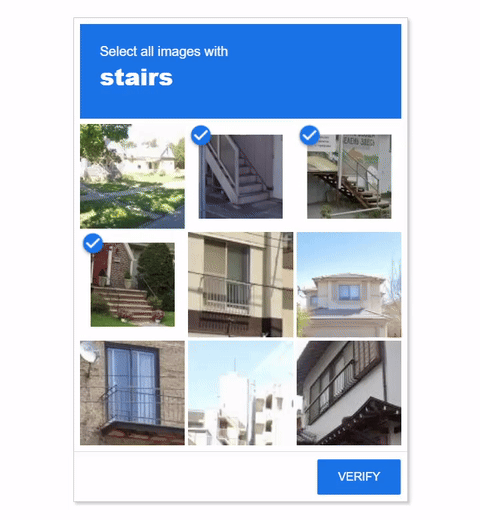
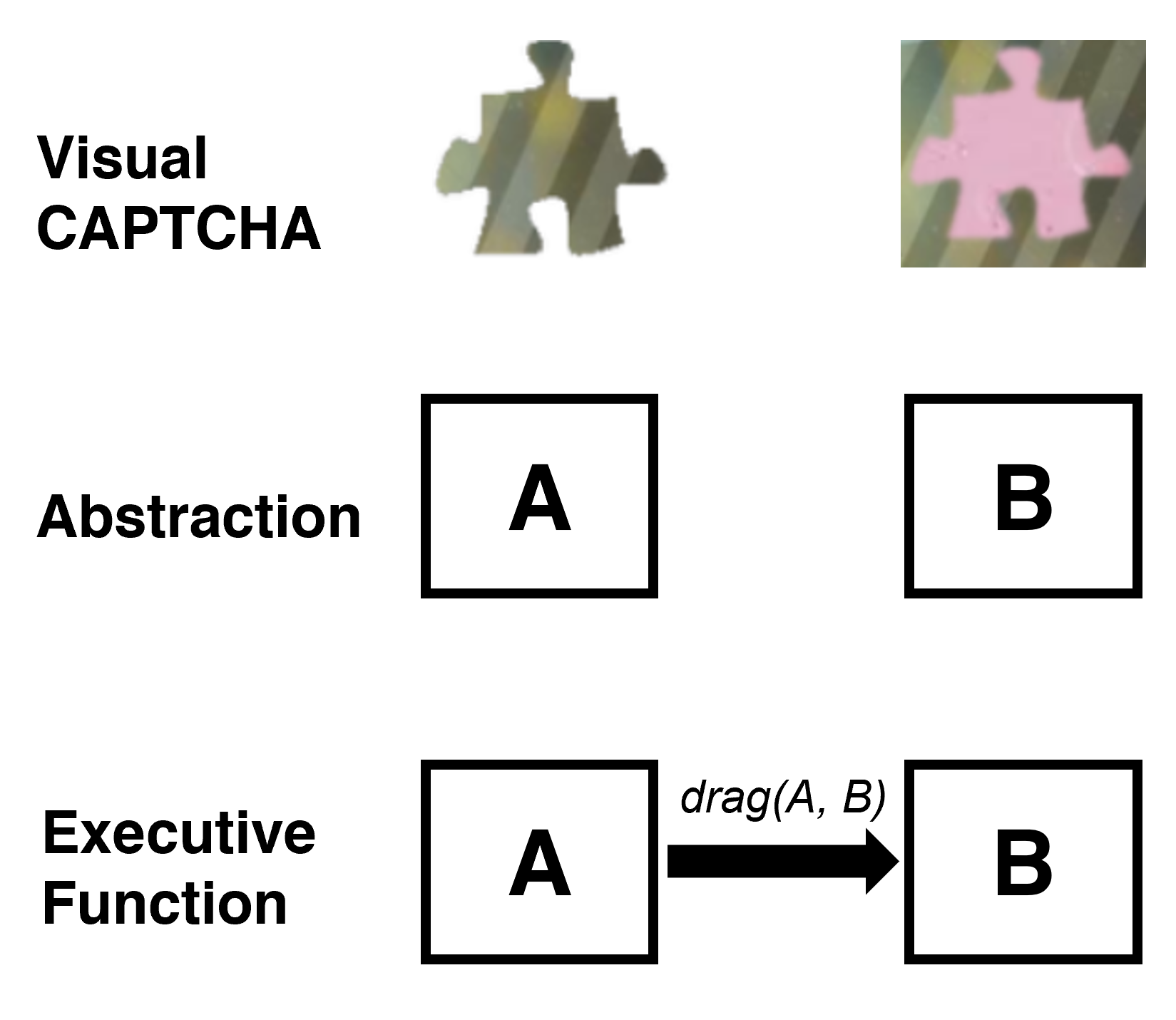
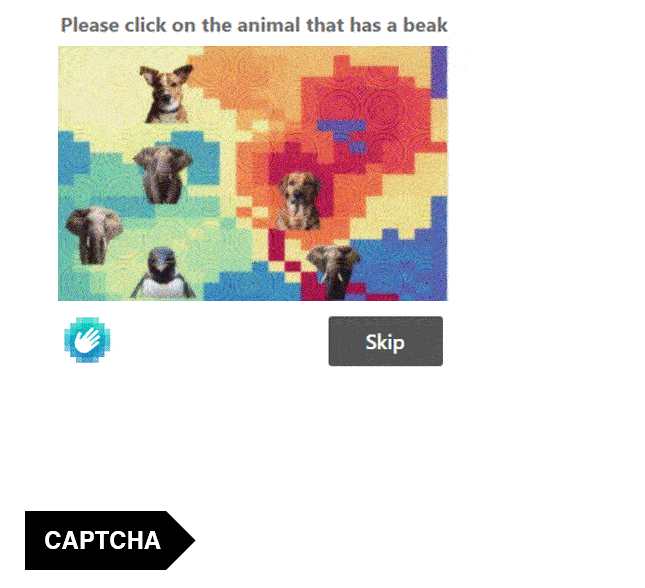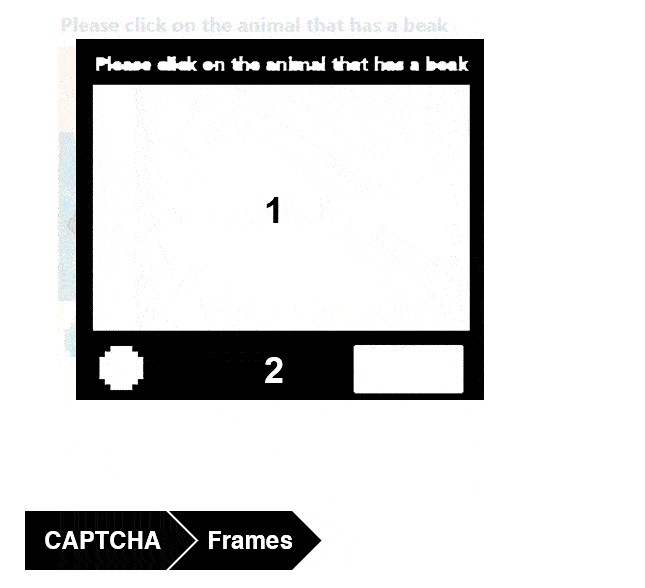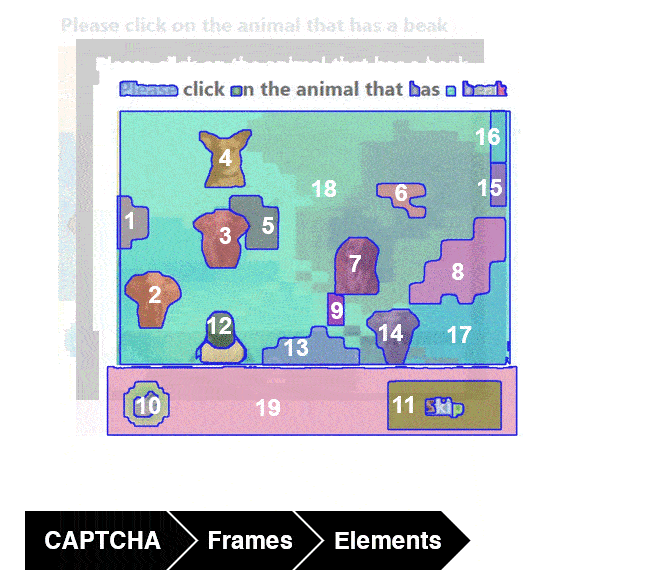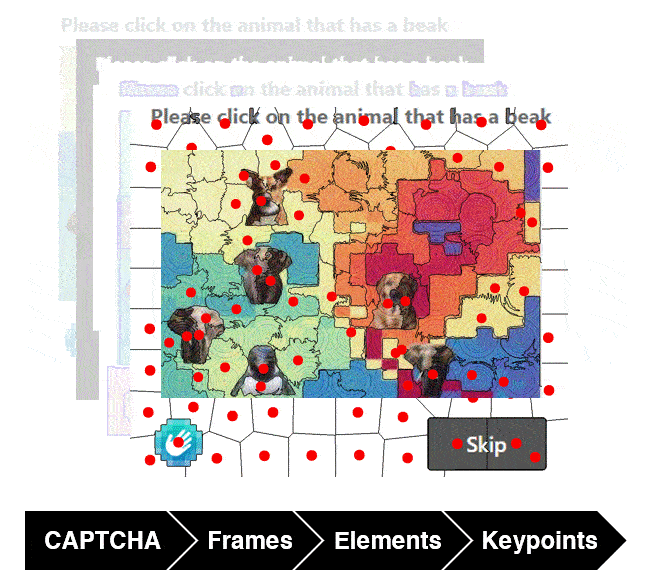
Visual CAPTCHAs, such as reCAPTCHA v2, hCaptcha, and
GeeTest, are mainstream security mechanisms to deter bots
online, based on the assumption that their puzzles are AI-hard but human-friendly. While many deep-learning based
solvers have been designed and trained to solve a specific
type of visual CAPTCHA, vendors can easily switch to out-of-distribution CAPTCHA variants of the same type or even
new types of CAPTCHA, with very low cost. However, the
emergence of general AI models (e.g., ChatGPT)
challenges the AI-hard assumption of existing CAPTCHA
practice, potentially compromising the reliability of visual
CAPTCHAs.
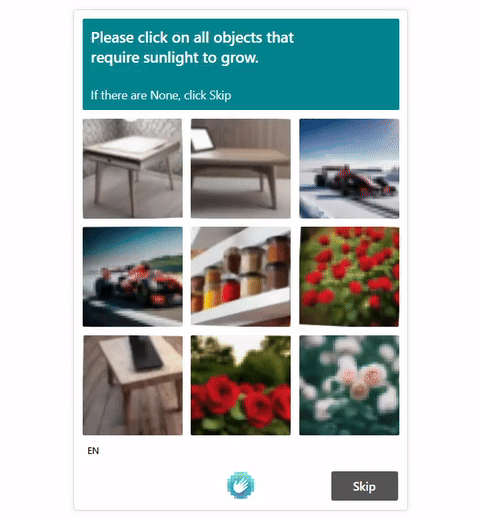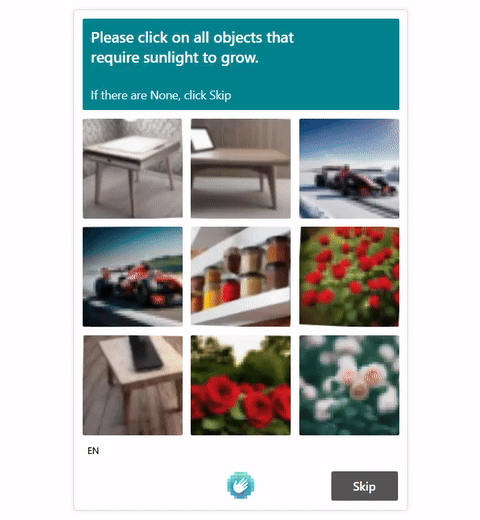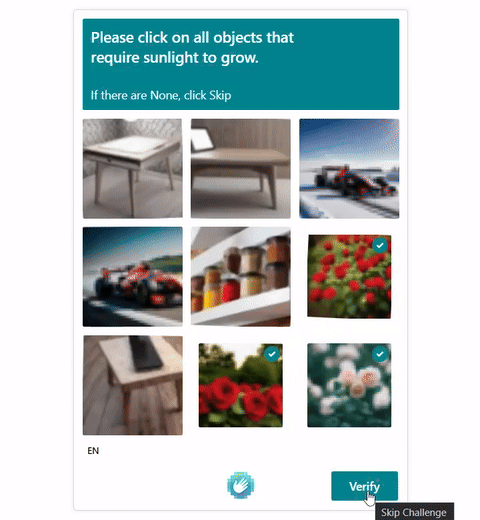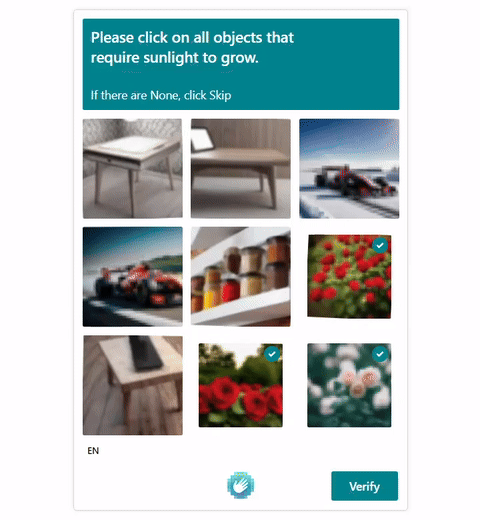
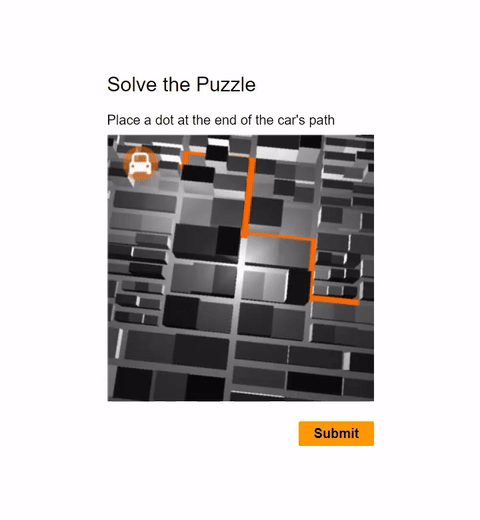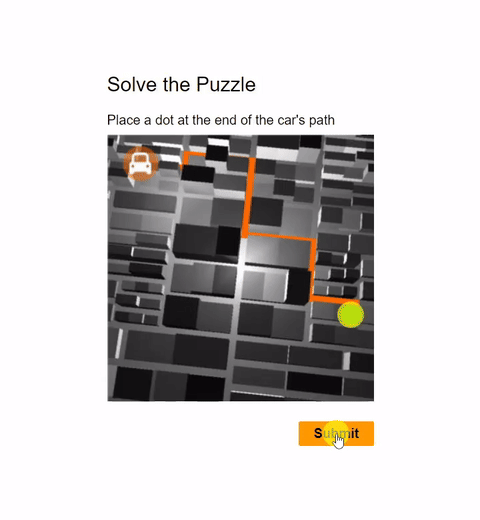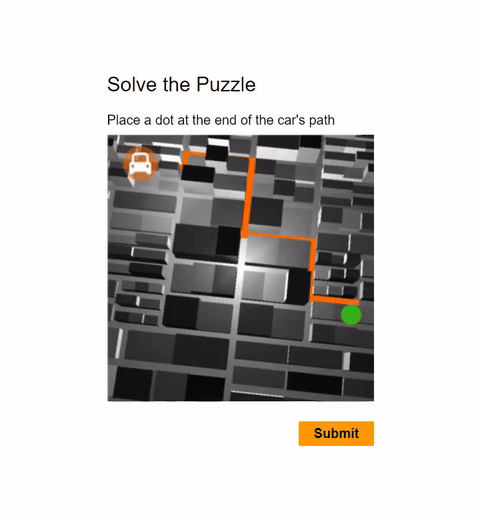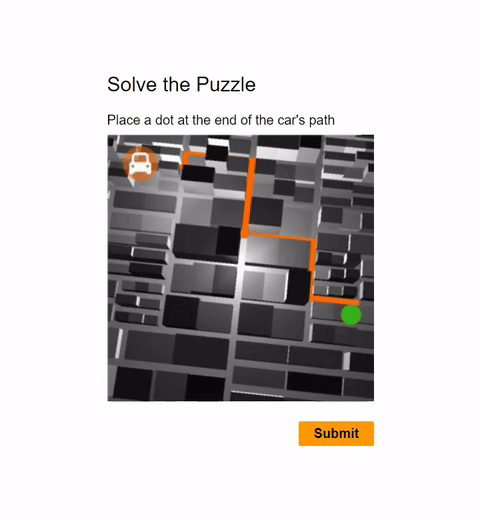
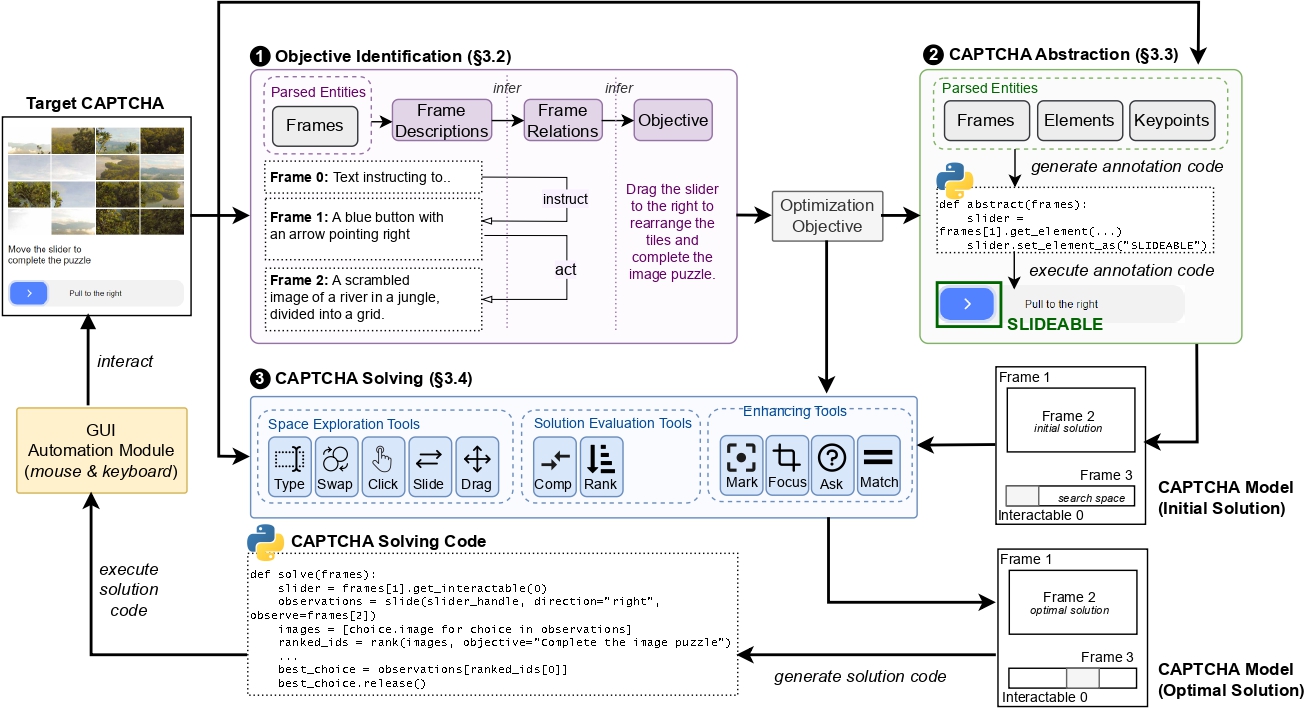
In this work, we report the first general CAPTCHA solving
solution, Halligan, built upon the state-of-the-art vision language model (VLM), which can effectively solve unseen visual CAPTCHAs without making any adaption. Our rationale
lies in that almost any CAPTCHA can be reduced to a search
problem where (i) the CAPTCHA question is transformed
into an optimization objective and (ii) the CAPTCHA body is
transformed into a search space for the objective. With well
designed prompts built upon known VLMs, the transformation can be generalized to almost any existing CAPTCHA.